Understanding Amazon Redshift Data Sharing Features
AWS Redshift is the data-warehousing solution provided by Amazon Web Services. As part of the Datawarehouse offering, Amazon Redshift provides a very useful feature known as data sharing. In this short article, we will get an understanding of when to use this feature and how to configure it in your own organization.
A data warehouse is a centralized repository designed to store, manage, and analyze large volumes of structured and semi-structured data from various sources. It is specifically optimized for querying, reporting, and data analysis.
What is Data Sharing?
Scenario 1 - Different clusters
In a large conglomerate with separate Amazon Redshift clusters dedicated to each division—such as finance, automotive, and manufacturing—you have a distributed data warehousing architecture where each division operates independently but still belongs to the overarching company infrastructure.
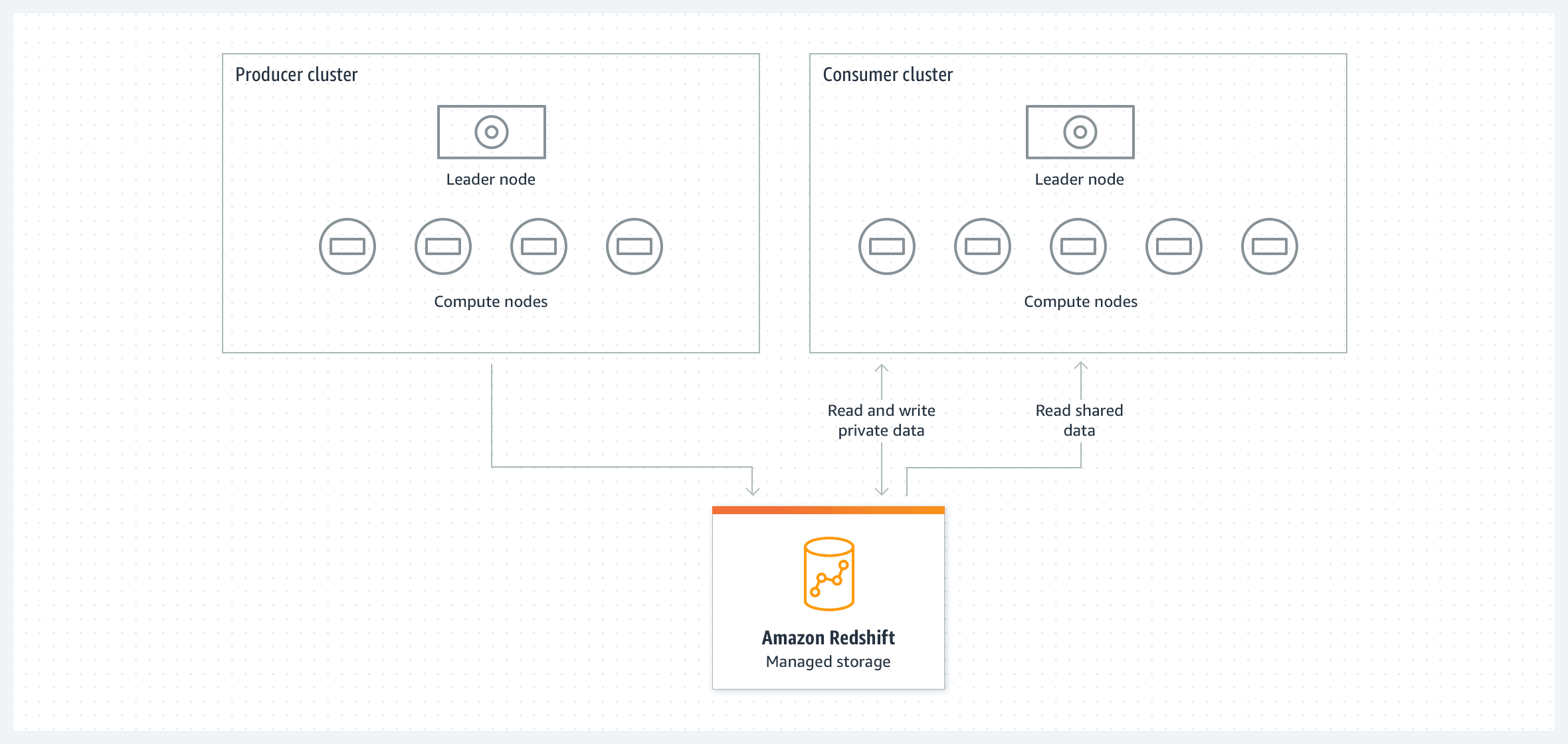
Joining datasets that reside on separate Amazon Redshift clusters—like joining data from the finance and manufacturing divisions—is achievable with Redshift Data Sharing. This feature allows seamless data access across clusters, avoiding the need to move or duplicate data.
Scenario 2 - Outsourcing compute
Another use case is sharing data with a third-party vendor without impacting the performance of your mission-critical Redshift cluster. In this scenario, you can set up a Redshift Serverless instance and configure data sharing for the specific datasets you want to share.
This allows the third-party vendor to access and analyze the shared data in the serverless environment without consuming compute resources from your primary ETL cluster. The serverless instance dynamically scales based on usage, ensuring that your main cluster’s resources remain fully dedicated to critical workloads.
How to configure data sharing?
To configure data sharing, we need to configure the source and the receiving cluster, or serverless instance. The terminology we will use is producer, and consumer.
Configure the producer
First, we will configure data sharing on the producer cluster so we can make the required data available to consume for the consumer (one or many)
-- As Admin User
-- Create datashare
CREATE DATASHARE shareData;
ALTER DATASHARE shareData ADD SCHEMA a_schema; -- Add target schema
ALTER DATASHARE shareData ADD TABLE a_schema.a_table; -- Add required tables to share
-- Grant permissions to required consumers
GRANT USAGE ON DATASHARE datashareDeviceLogs TO NAMESPACE 'CONSUMER_NAMESPACE_ID'; -- Share with consumer namespace
DESC DATASHARE shareData;
-- Needed if target cluster is set as publicly accessible
ALTER DATASHARE shareData SET PUBLICACCESSIBLE = TRUE;
GRANT ALTER, SHARE ON DATASHARE shareData TO GROUP the_group1; -- To allow group to manage this datashare
select * from svv_datashare_privileges; -- see who is allowed to alter datashares other than admin
Configure the consumer
Once datashare has been configured on the producer, we can login into the consumer as an admin user and run the below commands to consume and read from the shared data.
-- As Admin User
-- check for incoming datashares
SHOW DATASHARES;
DESC DATASHARE shareData OF NAMESPACE 'PRODUCER_NAMESPACE_ID';
-- Create a database to interact with the shared objects
CREATE DATABASE sharedData WITH PERMISSIONS FROM DATASHARE shareData OF NAMESPACE 'PRODUCER_NAMESPACE_ID';
---------------------------- Access using a external schema ----------------------------
--- using this configuration, the user cannot directly query the datashare database but through external schema ---
-- Create external schema poining to the datashare's database
CREATE EXTERNAL SCHEMA shared FROM REDSHIFT DATABASE sharedData SCHEMA 'a_schema';
-- Grant permissions
-- Usage access for datashare source schema (Note, we are not giving access to datashare itsself)
GRANT USAGE ON SCHEMA sharedData.a_schema TO GROUP a_group;
-- Access for external schema
GRANT USAGE ON SCHEMA shared.a_table TO GROUP a_group;
GRANT SELECT ON ALL TABLES IN SCHEMA sharedData.a_schema TO TO GROUP a_group; -- [PRIVELEGE] to target datashare table
With proper permissions set at the producer and consumer, the users and groups with proper permisisons will be able to query the shared data.
Limitations for data sharing
The following are limitations when working with datashares in Amazon Redshift:
Data sharing is supported for all provisioned ra3 cluster types (ra3.16xlarge, ra3.4xlarge, and ra3.xlplus) and Amazon Redshift Serverless. It isn't supported for other cluster types.
Amazon Redshift doesn't support adding external schemas, tables, or late-binding views on external tables to datashares.
Consumers can't add datashare objects to another datashare. Additionally, consumers can't add views referencing datashare objects to another datashare.
Amazon Redshift doesn't support sharing stored procedures through datashares.