Apache Spark Unified Memory

Introduction
Apache Spark, a powerful distributed processing engine, relies heavily on memory management for optimal performance.
The Unified Memory Manager (UMM) — introduced in Spark 1.6 — plays a key role in efficiently allocating and managing memory resources across executors in your cluster.
Understanding Memory Pools in Spark
To optimize Spark performance, it’s important to understand terms like:
Reserved memory
Executor memory
Executor memory fraction
Storage fraction
Overhead memory
The UMM manages two primary memory pools inside the broader executor memory:
🧠 Storage Memory
Used to:
Store RDDs when cached (
persist()/cache()).Hold broadcast variables for joins and lookups.
You can control it using:
spark.executor.storage.fraction
⚙️ Execution Memory
Used for active computations like:
Joins
Sorting
Aggregations
These operations rely on temporary in-memory structures to perform efficiently.
Reserved and Overhead Memory
🔸 Overhead Memory
Extra memory required for:
Off-heap operations
Task execution
JVM & YARN overhead
By default:
max(384MB, 10% of executor memory)
is allocated as overhead — typically sufficient for most workloads.
🔸 Reserved Memory
Spark internally reserves 300 MB for metadata and non-execution operations.
This space is not available to storage or execution tasks.
Simple Example
Consider a Spark job running on a node with 20 GB total memory.
You allocate:
spark.executor.memory = 10G
spark.executor.offHeap.memory = 1G
Here’s how Spark divides memory:
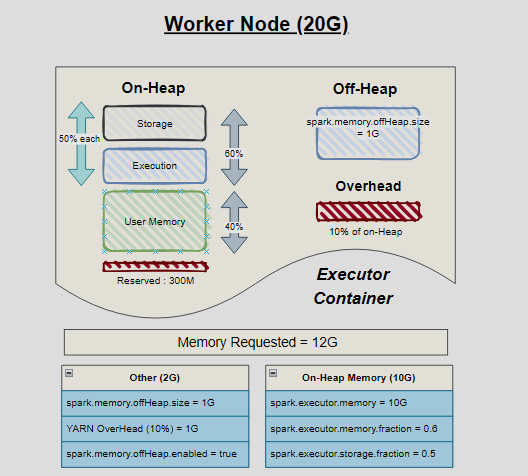
| Type | Description |
|---|---|
| Overheads (1G) | Memory for JVM, YARN, and Spark internal processes — shown as red blocks. |
| On-Heap (10G) | JVM-managed memory. Subject to Garbage Collection (GC). If GC times are high, move some data to off-heap. |
| Off-Heap (1G) | Outside JVM control, managed by OS. Reduces GC pressure and improves performance for heavy compute workloads. |
Memory Split Inside On-Heap Memory
| Memory Type | Config | Default | Description |
|---|---|---|---|
| Execution Memory | spark.memory.fraction |
0.75 | Used for shuffle, joins, sorts, aggregations |
| Storage Memory | spark.memory.storageFraction |
0.5 | Portion of unified memory reserved for caching/persistence |
| User + Reserved Memory | N/A | Remaining | Used for user data structures, Spark internals |
Optimization Tips
✅ Tune Memory Fractions
Adjust spark.executor.memory.fraction and spark.executor.storage.fraction based on workload type (compute vs cache heavy).
✅ Monitor & Tune
Regularly review Spark UI or CloudWatch metrics to detect GC issues, OOM errors, and shuffle spills.
✅ Use Efficient Data Structures
Prefer DataFrames or Datasets over RDDs. They use Catalyst optimization and are more memory efficient.
✅ Enable Off-Heap Memory
Useful for long-running jobs where GC overhead becomes significant.
Memory Calculator (Interactive Concept)
A simple visualization to understand how Spark divides memory:
https://codepen.io/pulkit42041/pen/XJXPMjE
Tweak these values to find the optimal balance for your workloads.
Conclusion
Understanding Apache Spark’s memory model is essential for performance tuning.
By knowing how Spark partitions memory between execution, storage, and overhead, you can:
Reduce OOM errors
Improve shuffle performance
Speed up caching and re-use
💡 Caching can drastically accelerate pipelines that reuse the same data across stages.
Broadcast joins help optimize large joins when one table fits in executor memory.
References:
Caching in Spark — Store intermediate RDDs to reuse results.
Broadcast Joins — Send small lookup tables to executors for fast map-side joins.