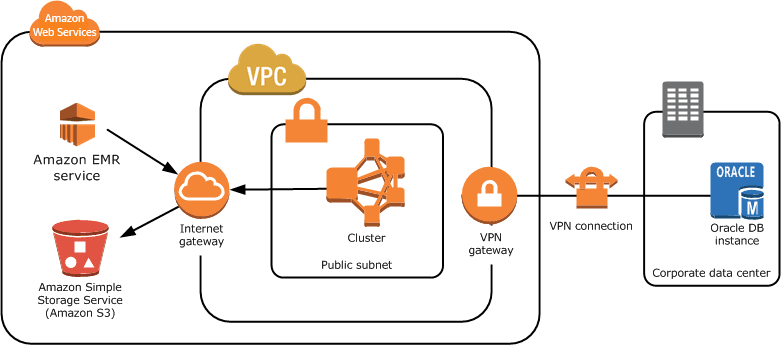
Apache Hadoop — Background
Technologies come and go, but data is here to grow! Introduction Data is the core of every modern application, driving insights, automation, and user experiences. Over time, technologies have evolved
May 20, 20255 min read15